QUESST 2014 Multilingual Database for Query-by-Example Keyword Spotting
Link to database: quesst14Database.tgz [1 116 MB]
The QUESST 2014 search dataset consists of 23 hours or around 12.500 spoken documents in the following languages: Albanian, Basque, Czech, non-native English, Romanian and Slovak. The languages were chosen so that relatively little annotated data can be found for them, as would be the case for a ``low resource'' language. The recordings were PCM encoded with 8 KHz sampling rate and 16 bit resolution (down-sampling or re-encoding were done when necessary to homogenize the database). The spoken documents (6.6 seconds long on average) were extracted from longer recordings of different types: read, broadcast, lecture and conversational speech. Besides language and speech type variability, the search dataset also features acoustic environment and channel variability. The distribution of spoken documents per language is shown in Table 1. The database is free for research purposes. Feel free to use the setup for evaluation and comparison of you results with results achieved by others and MediaEval QUESST 2014 evaluations.
Here (http://ceur-ws.org/Vol-1263/mediaeval2014_submission_35.pdf) you can find the MediaEval QUESST 2014 task description, and here (http://ceur-ws.org/Vol-1263/) are the system descriptions of particular teams which participated in MediaEval QUESST 2014 evaluations. An overview paper discussing achieved results is published at ICASSP 2015 and is available here. If you publish any results based on this QUESST2014 database, please refer the paper (bibtex).
Table 1: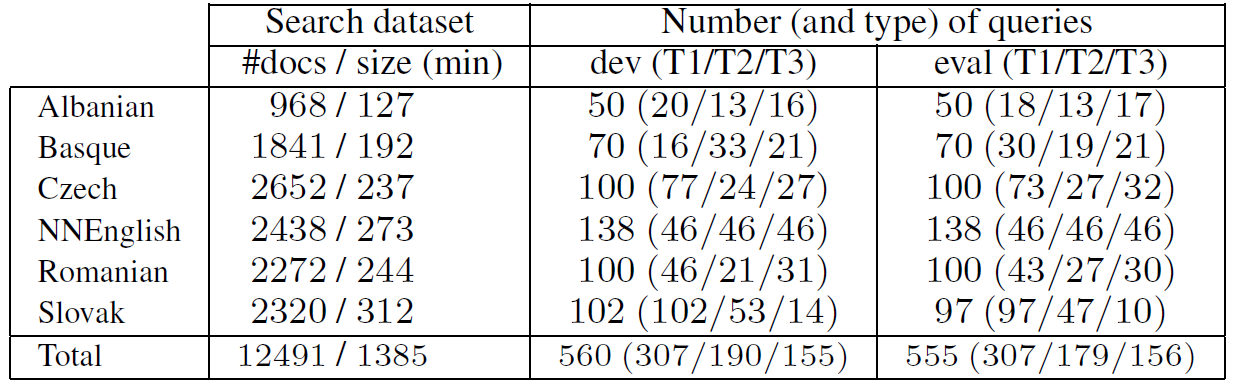
According to the spoken language and the recording conditions, the database is organized into 5 language subsets:
Albanian & Romanian:
Read speech by 10 Albanian and 20 Romanian speakers (gender balanced). Queries were recorded by different speakers within the same environment.
The speech utterances are recorded in lab conditions at 16kHz and they are later down sampled to 8kHz.
Basque:
Mixture of read and spontaneous speech recorded from broadcast news programs, including some studio and outdoors (noisy) recordings. Queries were recorded with a digital recorder (using a close-talk microphone) in an office environment by different speakers (gender balanced). The utterances from the search repository are extracted from broadcast news originally recorded at 16kHz and then re-sampled at 8kHz. The speech type is a mixture of planned and spontaneous, while the recording quality is of both studio and outdoor (noisy) environment. The Basque subset features both channel and speaker mismatch between the search utterances and the queries.
Czech:
Conversational (spontaneous) speech obtained from telephone calls into radio live broadcasts, mixing some clean (majority) and noisy acoustic conditions. Queries were recorded by 12 speakers (3 non-native) using a mobile application (total acoustic mismatch) at 8kHz. As the utterances comes from conversational speech and queries are dictated, this incorporates large speaking style mismatch and also channel mismatch.
Non-native English:
The main corpus was compiled from a variety of TED talks with non-native, but skilled English speakers. Transcriptions were automatically aligned with the audio to generate the references. Queries were spoken in clean conditions by non-native (Chinese, Indian, German, and Italian) English speakers of intermediate proficiency.
Slovak:
Spontaneous speech, recorded from Parliament meetings using stationary microphones, in mainly clean conditions (90\% male speakers). Queries were recorded in clean lab conditions.
In addition to the search data, two sets of audio queries were prepared: 560 queries for development, and 555 queries for evaluation. This year, the queries were not extracted (i.e.~"cut") from longer recordings, in order to avoid imposing acoustic context. Instead, they were recorded manually and the recruited speakers were asked to pronounce the queries in isolation, at a normal speaking rate and using a clear speaking style to simulate a regular user querying a retrieval system via speech. Three types of queries were recorded, in order to evaluate the performance of systems against different kinds of matchings that users expect in a real-life scenario:
Type 1 ("T1"):
Queries containing single or multiple words that should match {\em exactly} the lexical form of the occurrences in the search data. For example, the query ''white horse'' would match the utterance ''My white horse is beautiful''. This type of query is the same as in SWS2013.
Type 2 ("T2"):
Queries containing small morphological variations with regard to the lexical form of the occurrences in the search data. For example, inflectional forms of a lexeme or added /omitted prefixes and suffixes should be correctly matched. In all cases, the matching part of any query is set to be at least 5 phonemes (approximately 250ms) long and the non-matching part to be much smaller. For example, the query "researcher" should match an utterance containing "research" (note that the inverse would also be possible).
Type 3 ("T3"):
Queries containing multiple words with syntactic (word reordering) or morpho-syntactic (reordering + intraword changes) differences with regard to the lexical form of the occurrences in the search data. For example, the query ``snow white'' should match the occurrence ``white snow'' as well as ``white snow'' and ``whiter snow''. Note that there should not be any silence between words as queries and utterances are pronounced fluently. Treating such a configuration as a match may not be appropriate in all languages, but the present work investigates the potential of search techniques to support this case, if required.
Note that any given query may appear in the database as any of the types described above. The information about query types and languages was not available to participants during the evaluation, so that systems were implicitly required to be robust to these variants.