Software
Phoneme recognizer based on long temporal context
The phoneme recognizer was developed at Brno University of Technology, Faculty of Information Technology and was successfully applied to tasks including language identification [4], indexing and search of audio records, and keyword spotting [5]. The main purpose of this distribution is research. Outputs from this phoneme recognizer can be used as a baseline for subsequent processing, as for example phonotactic language modeling.
VBHMM x-vectors Diarization (aka VBx)
Diarization recipe for winning system of track 1 of The Second DIHARD Diarization Challenge by Brno University of Technology. The recipe consists of
- computing fbank features
- computing x-vectors
- doing Agglomerative Hierarchical Clustering on x-vectors as a first step to produce an initialization
- apply Variational Bayes HMM over x-vectors to produce the diarization output
- score the diarization output
Related publications:
DIEZ Sánchez Mireia, BURGET Lukáš, LANDINI Federico Nicolás and ČERNOCKÝ Jan. Analysis of Speaker Diarization based on Bayesian HMM with Eigenvoice Priors. IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, vol. 28, no. 1, pp. 355-368. ISSN 2329-9290. https://www.fit.vut.cz/research/publication/12139/
F. Landini, S. Wang, M. Diez, L. Burget, P. Matějka, K. Žmolíková, L. Mošner, A. Silnova, O. Plchot, O. Novotný, H. Zeinali, J. Rohdin: BUT System for the Second DIHARD Speech Diarization Challenge, accepted to ICASSP 2020, Barcelona
M. Diez, L. Burget, F. Landini, S. Wang, J. Černocký: Optimizing Bayesian HMM based x-vector clustering for the second DIHARD speech diarization challenge, accepted to ICASSP 2020, Barcelona
Link to GitHub: https://github.com/BUTSpeechFIT/VBx
BUT Speech@FIT Reverb Database
This is the first release of BUT Speech@FIT Reverb Database. The database is being built with respect to collect a large number of various Room Impulse Responses, Room environmental noises (or "silences"), Retransmitted speech (for ASR and SID testing), and meta-data (positions of microphones, speakers etc.).
The goal is to provide speech community with a dataset for data enhancement and distant microphone or microphone array experiments in ASR and SID.
The database has CC-BY 4.0 license and you can download it here:
- Room impulse responses, environmental noises, and metadata only: BUT_ReverbDB_rel_19_06_RIR-Only.tgz [8.7 GB]
- Librispeech retransmission only: BUT_ReverbDB_rel_19_06_LibriSpeech-Only.tgz [117 GB]
If you want to publish a paper using this dataset, please cite: https://ieeexplore.ieee.org/document/8717722 (DOI:10.1109/JSTSP.2019.2917582, https://arxiv.org/abs/1811.06795) and refer to this page.

Multilingual Region-Dependent Transforms
This shell package allows to extract features based on Region Dependent Transforms (RDT) models from audio files. The features are well suitable mainly for Gaussian Mixture Models (GMM) in Automatic Speech Recognition (ASR) systems but they could be used in other applications as well.
The whole process could be split into 3 steps. Standard PLP-HLDA features are concatenated with Stacked Bottle-Neck Features trained in multilingual fashion on Babel data coming from 17 different languages. This features are going into discriminatively trained RDT transforms on 17 Babel languages which generates final outputs.
BUT/Phonexia Bottleneck feature extractor
This python package allows to extract bottleneck, stacked bottleneck features and phoneme/senones posteriors from audio files. Primarily, bottleneck features are tuned for the task of spoken language recognition but can be used in other applications (e.g. speaker recognition, speech recognition) as well. Package includes three neural networks i.e. there are three types of features one can extract with it. Two networks are trained on English data only and the third is trained in multilingual fashion on data coming from 17 different languages. Also, there is a possibility to extract phoneme classes posteriors, create phoneme strings (one best), lattices and summed soft counts.
Speaker Diarization based on Bayesian HMM with Eigenvoice Priors
This python code implements speaker diarization algorithm described in:
Diez Mireia, Burget Lukáš and Matějka Pavel. Speaker Diarization based on Bayesian HMM with Eigenvoice Priors. In: Proceedings of Odyssey 2018. Les Sables d´Olonne: International Speech Communication Association, 2018, pp. 147-154. ISSN 2312-2846. available at: http://www.fit.vutbr.cz/research/groups/speech/publi/2018/diez_odyssey2018_63.pdf
Abstract:
Nowadays, most speaker diarization methods address the task in two steps: segmentation of the input conversation into (preferably) speaker homogeneous segments, and clustering. Generally, different models and techniques are used for the two steps. In this paper we present a very elegant approach where a straightforward and efficient Variational Bayes (VB) inference in a single probabilistic model addresses the complete SD problem. Our model is a Bayesian Hidden Markov Model, in which states represent speaker specific distributions and transitions between states represent speaker turns. As in the i-vector or JFA models, speaker distributions are modeled by GMMs with parameters constrained by eigenvoice priors. This allows to robustly estimate the speaker models from very short speech segments. The model, which was released as open source code and has already been used by several labs, is fully described for the first time in this paper. We present results and the system is compared and combined with other state-of-the-art approaches. The model provides the best results reported so far on the CALLHOME dataset.
Download: http://www.fit.vutbr.cz/~burget/VB_diarization.zip (attention, the file has 35 MB as it contains example data).
QUESST 2015 Multilingual Database for Query-by-Example Keyword Spotting
Links to files:
- QUESST2015_deveval_groundtruth_scoring.tgz [2,8 MB]
- QUESST2015-dev_v2.tgz [1046 MB]
- QUESST2015-eval.tgz [45,6 MB]
- scoring_quesst2015_v2.tgz [25,3 MB]
If you publish any paper regarding QUESST 2015, please cite Query by Example Search on Speech at Mediaeval 2015 (Igor Szoke, Luis Javier Rodriguez-Fuentes, Andi Buzo, Xavier Anguera, Florian Metze, Jorge Proenca, Martin Lojka, Xiao Xiong)
The task of QUESST ("QUery by Example Search on Speech Task") is to search FOR audio content WITHIN audio content USING an audio query. As in previous years, the search database was collected from heterogeneous sources, covering multiple languages, and under diverse acoustic conditions. Some of these languages are resource-limited, some are recorded in challenging acoustic conditions and some contain heavily accented speech (typically from non-native speakers). No transcriptions, language tags or any other metadata are provided to participants. The task therefore requires researchers to build a language-independent audio-to-audio search system.
QUESST 2014 Multilingual Database for Query-by-Example Keyword Spotting
Link to database: quesst14Database.tgz [1 116 MB]
The QUESST 2014 search dataset consists of 23 hours or around 12.500 spoken documents in the following languages: Albanian, Basque, Czech, non-native English, Romanian and Slovak. The languages were chosen so that relatively little annotated data can be found for them, as would be the case for a ``low resource'' language. The recordings were PCM encoded with 8 KHz sampling rate and 16 bit resolution (down-sampling or re-encoding were done when necessary to homogenize the database). The spoken documents (6.6 seconds long on average) were extracted from longer recordings of different types: read, broadcast, lecture and conversational speech. Besides language and speech type variability, the search dataset also features acoustic environment and channel variability. The distribution of spoken documents per language is shown in Table 1. The database is free for research purposes. Feel free to use the setup for evaluation and comparison of you results with results achieved by others and MediaEval QUESST 2014 evaluations.
Here (http://ceur-ws.org/Vol-1263/mediaeval2014_submission_35.pdf) you can find the MediaEval QUESST 2014 task description, and here (http://ceur-ws.org/Vol-1263/) are the system descriptions of particular teams which participated in MediaEval QUESST 2014 evaluations. An overview paper discussing achieved results is published at ICASSP 2015 and is available here. If you publish any results based on this QUESST2014 database, please refer the paper (bibtex).
Table 1: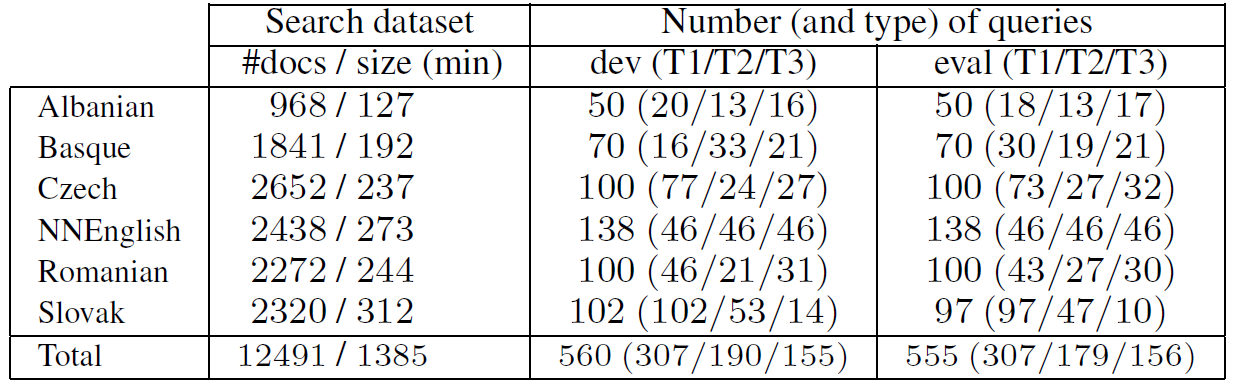
SWS 2013 Multilingual Database for Query-by-Example Keyword Spotting
Link to database: sws2013Database.tgz
The database used for the SWS 2013 evaluation has been collected thanks to a joint effort from several participating institutions that provided search utterances and queries on multiple languages and acoustic conditions (see Table 1). The database is available to the community for research purposes. Fell free to evaluate your query-by-example approaches for keyword spotting (spoken term detection). The database contains 20 hours of utterance audio (the data you search in), ~500 development and ~500 evaluation audio queries (the data you search for), scoring scripts and references.
Here (http://ceur-ws.org/Vol-1043/mediaeval2013_submission_92.pdf) you can find the MediaEval SWS2013 task description, and here (http://ceur-ws.org/Vol-1043/) are the system descriptions of particular teams which participated in MediaEval SWS2013 evaluations. An overview paper discussing achieved results was published at SLTU 2014 and is available here. If you publish any results based on this SWS2013 database, please refer the paper (bibtex).
RNNLM Toolkit
Neural network based language models are nowdays among the most successful techniques for statistical language modeling. They can be easily applied in wide range of tasks, including automatic speech recognition and machine translation, and provide significant improvements over classic backoff n-gram models. The 'rnnlm' toolkit can be used to train, evaluate and use such models.
The goal of this toolkit is to speed up research progress in the language modeling field. First, by providing useful implementation that can demonstrate some of the principles. Second, for the empirical experiments when used in speech recognition and other applications. And finally third, by providing a strong state of the art baseline results, to which future research that aims to "beat state of the art techniques" should compare to.
Speech search
Source code of three systems for speech search is available here:
- Example data (few HTK lattices with scripts for generating bin sequences and sqlcopy files from HTK lattices)
- Lucene extension for bin sequences (source code, Lucene 3.0.0 binaries, Jetty configuration)
- PostgreSQL extension for bin sequences (source code)
- LSE (source code) ...link to it's own page
Each archive has a README file included which should be helpful for your first steps with the systems.
Neural Network Trainer TNet
Thanks for the interest in TNet! At the moment let's consider it as a dead project, as I fully switched the efforts to 'nnet1' recipe in kaldi: http://kaldi.sourceforge.net/dnn1.html. You can still use the TNet, but it is not to be extended anymore. Thanks!
TNet is a tool for parallel training of neural networks for classification, containing two independent sets of tools, the CPU and GPU tools. The CPU training is based on multithread data-parallelization, the GPU training is implemented in CUDA, both are implementing mini-batch Stochastic Gradient Descent, optimizing per-frame Cross-entropy.
The toolkit contains example of NN training on TIMIT, which can be easily transfered to your data. You may also be interested in hierarchical "Universal Context Network" a.k.a. "Stacked bottleneck netowork", which can be built using one-touch-script : tools/train/tnet_train_uc.sh
Lattice Spoken Term Detection toolkit (LatticeSTD)
Toolkit for experiments with lattice based spoken term detection. It allows you to define set of terms and search them in lattices.
Precisely:
- Searches for defined sequence of links in lattice and outputs label assign to this sequence.
- Calculates confidence of found sequence (posterior probability)
- Filter overlapped detection
- Allows handle substitutions/deletion/insertion (useful for phone lattices)
KWSViewer - Interactive viewer for Keyword spotting output
This tool can load an output of a keyword-spotting system (KWS) and reference file in HTK-MLF format and show detections in a tabular view. You can also use it to replay detections, tune and visualize scores, hits, misses and false-alarms using sliders on the right-side panel.
Joint Factor Analysis Matlab Demo
This set of Matlab functions and data by Ondrej Glembek (glembek@fit.vutbr.cz) is a simple tutorial of Joint Factor Analysis (JFA), as it was investigated at the JHU 2008 workshop http://www.clsp.jhu.edu/workshops/ws08/groups/rsrovc/.
HMM Toolkit STK
A set of tools for training and recognition of HMM's. Probably the most interesting in this distribution is SERest - a tool for embedded training of HMM's with supporting scripts. Key features of SERest include re-estimation of linear transformations (MLLT, LDA, HLDA) within the training process, and use of recognition networks for the training.